An Efficient Algorithm for Multimodal Medical Image
Fusion based on Feature Selection and PCA Using DTCWT (FSPCA-DTCWT)
Type of article: Original Article
Abstract:
Background:
During the two past decades, medical image fusion has become an essential
part of modern medicine due to the availability of numerous imaging modalities
(MRI, CT, SPECT, etc.). This paper presents a new medical image fusion
algorithm based on DTCWT and uses different fusion rules in order to obtain a
new image which contains more information than any of the input images.
Methods: A new image fusion
algorithm improves the visual quality of the fused image, based on feature
selection and Principal Component Analysis (PCA) in the Dual-Tree Complex
Wavelet Transform (DTCWT) domain. It is called Feature Selection with Principal
Component Analysis and Dual-Tree Complex Wavelet Transform (FSPCA-DTCWT). Using
different fusion rules in a single algorithm result in correctly reconstructed
image (fused image), this combination will produce a new technique, which
employs the advantages of each method separately. The DTCWT presents good
directionality since it considers the edge information in six directions and
provides approximate shift invariant. The main goal of PCA is to extract the
most significant characteristics (represented by the wavelet coefficients) in
order to improve the spatial resolution. The proposed algorithm fuses the
detailed wavelet coefficients of input images using features selection rule
Results: Several experiments have been conducted over
different sets of multimodal medical images such as CT/MRI, MRA/T1-MRI.
However, due to pages-limit on a paper, only results of three sets have been
presented. The FSPCA-DTCWT algorithm is compared to recent fusion methods
presented in the literature (eight methods) in terms of visual quality and
quantitatively using well-known fusion performance metrics (five metrics).
Results showed that the proposed algorithm outperforms the existing ones
regarding visual and quantitative evaluations.
Conclusion:
This paper focuses on image fusion of medical images obtained from
different modalities. A novel image fusion algorithm based on DTCWT to merge
multimodal medical images, has been proposed. Experiments have been performed
over two different sets of multimodal medical images. The results show
that the proposed fusion method significantly outperforms the recent fusion
techniques reported in the literature.
Keywords:
Multimodal medical images; Image fusion; DTCWT; PCA; Feature selection
Corresponding author: Abdallah Bengueddoudj, Department of Electrical
Engineering, University of BordjBouArreridj, BordjBouArreridj, Algeria
Email: beng.abdallah@hotmail.com
Received: June
30, 2017, Accepted: December 12, 2017, English editing: February 25, 2018,
Published: March 19, 2018.
Screened by
iThenticate. ©2017KNOWLEDGE KINGDOM PUBLISHING.
1. INTRODUCTION
Nowadays, medical image fusion has become a useful and important tool in
surgical interventions and diagnostics. The principle of image fusion is based
on the combination of information from multiple images obtained from different
sensors into a single image [1]. The objective of image fusion is to preserve the
most important features of each source images. The latter one, are captured
using different biomedical detectors, which are used to extract complementary
information about human tissues. Different medical imaging modalities such as
Magnetic Resonance Image (MRI), Computed Tomography (CT), Positron Emission
Tomography (PET) and Single Photon Emission Tomography (SPECT) can localize the
abnormal masses and give an easy overview of the anatomic detail. Imaging
methods have their own characteristics and limitations. As an example, CT
images take excellent picture of bones and other dense structures whereas MR
images are perfectly describing information about soft tissues
Similarly, the MR images have higher spatial resolution than the PET
images, which provides anatomical information without functional activity.
Hence, we can conclude that these complementarities may be combined in order to
generate an image that can offer more information than any of the individual
source images. For example, medical PET/CT imaging is used for cancer
detection, SPECT/CT fusion [2]in abdominal studies, and MRI/PET for brain tumor
detection. Similarly, MRI/CT and PET/SPECT imaging [3]contribute to planning surgical procedure. In this
case, the purpose of medical image fusion is to obtain an image with high
spatial resolution and also integrates both functional and anatomical
information.
In the present work, we have proposed a novel architecture with a hybrid
algorithm based on DTCWT, the developed fusion algorithm (FSPCA-DTCWT)
integrates different fusion rules to combine the wavelet coefficients of
multimodal medical image fusion method. FSPCA-DTCWT is compared to recent
fusion methods presented in the literature in terms of visual quality and
quantitatively using the well-known fusion performance metrics. The rest of
this paper is organized as follows: Image fusion literature is discussed in
Section 2. Properties of DTCWT are described in Section 3. Section 4 explains
the proposed fusion algorithm (FSPCA-DTCWT). Experimental results and
performance evaluations are given in Sections 5. Finally, conclusions of the
work are given in Section 6.
2. Procedure for Background
and Literature
Many fusion methods have been proposed in the
literature. These methods can be performed at three different levels depending
on the stage at which the combination mechanism takes place, namely: pixel
level, feature level and decision level [5]. Fusion at pixel-level is performed
directly on the values derived from the pixels of the source images on a
pixel-by-pixel basis to generate a single fused image. Feature level image
fusion is one level higher than the pixel-level image fusion. Methods belong to
this level represent used region based fusion scheme. The input images are
divided (segmented) into regions, and various region properties can be
calculated and used to determine which features from each original image are
used in the fused image. In general, the fusion process at any level should
always preserve all possible important information existed in the source
images; on the other hand, the fusion process should be able to generate an
image without introducing any artefacts, noise, unpredicted characteristic or
loss of information [6].
Several pixel-level fusion algorithms have been
developed and can be broadly classified as [7] substitution techniques,
transform domain methods and optimization approaches (relying on Bayesian
models, fuzzy logic and neural networks to name a few). This work employs the
first two types of fusion.
Substitution techniques such as Principal Component
Analysis (PCA), weighted averaging, Intensity Hue Saturation (IHS), averaging
and weighted averaging are the simplest way to perform image fusion. The fused
image is reconstructed by calculating the simple mean of the source images
pixel-by-pixel or obtained by using the weighted averaging approach. In this
method, weights are calculated according to the neighbourhood of each pixel.
However, these methods suffer from contrast degradation and artefacts in the
fused images.
Transform domain techniques overcome the limitations
of the substitution methods. These techniques comprise multiresolution
decomposition, Wavelet Transform (WT), Laplacian Pyramid (LP), and other
multidirectional transforms relying on the Contourlet Transform, and the
Curvelet Transform. The LPand WT are the most well-known multiresolution
approaches widely used in image fusion. In general, the Discrete Wavelet
Transform (DWT) methods perform better than LP procedures [8].
The WT is exponentially proliferating in many image
processing tasks, including compression, denoising, feature extraction, inverse
problems, image enhancement, restoration and image fusion, because of it
provides good directional information and offers a better representation in the
decomposed components’ domain and better results than the Pyramid Transform
(PT) [9].
The Discrete Wavelet Transform (DWT) is a popular
Wavelet Transform used in image fusion. DWT-based fusion methods outperform the
conventional image fusion methods based on the PT, regarding a proper
localization in both the spatial and the frequency domains, and the ability to
capture significant information of the input image. DWT provides good spectral
information and better directional information along three spatial orientations
(vertical, horizontal, and diagonal) as compared to pyramid representations.
Furthermore, the DWT provides other important features like excellent energy
compaction by representing the entire image information using few significant
coefficients and offers higher flexibility in choosing an appropriate basis
function to develop new and efficient image fusion methods. Therefore, these
essential properties of the DWT lead the researchers to develop DWT-based
fusion algorithms for a variety of image data sets such as multi-focus images,
panchromatic and multispectral satellite images, infrared and visible images.
Wavelet-based fusion methods were presented by Li et
al. [10] relying on the DWT and including a maximum selection rule to determine
which of the wavelet coefficients contain the relevant information, within a
centered window. The major shortcoming of this method is the use of the same
fusion rule for combining both approximation coefficients (low-frequency subbands)
and detail coefficients (high-frequency subbands). Since the wavelet and detail
coefficient have different characteristics, we have proposed two distinguished
fusion rules to merge the coefficients of approximation subbands as well as the
detail subbands separately.
Several research works have showed that DWT suffers
from shift sensitivity, the absence of phase information and poor
directionality [9]. To remove out these limitations, DTCWT [11-12] inherits all
the advantages of wavelet transform and provide an approximate shift invariant
with better directionality than DWT, and provide perfect reconstruction using
short linear-phase filters, orthogonality and
symmetry
properties. For these reasons, we have chosen DTCWT and incorporate two
different fusion rules in our developed fusion algorithm.
3. The 2-D Dual-Tree Complex
Wavelet Transform
In the multi-resolution context, any function![]() ) of size
) of size ![]() can be represented as:
can be represented as:
|
|
(1) |
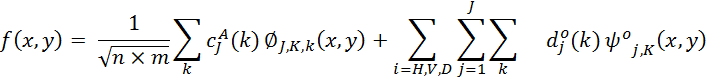
Where![]() is the largest level of decomposition and
is the largest level of decomposition and ![]() denotes
coefficients in the approximate subband in this level.
denotes
coefficients in the approximate subband in this level.![]() represents the detail coefficient in the level
represents the detail coefficient in the level![]() ) of orientation
) of orientation ![]() . Here
. Here![]() and
and ![]() mean the three
subbands which contain detail information in the horizontal, vertical, and the
diagonal directions, respectively. The 2-D scaling
mean the three
subbands which contain detail information in the horizontal, vertical, and the
diagonal directions, respectively. The 2-D scaling ![]() and the three
2-D wavelet
and the three
2-D wavelet ![]() functions are
obtained using the product of their associated 1-D scaling and wavelet
functions [12]. The proposed method uses DTCWT which is
an extension of the DWT. The DTCWT, as the name implies, it consists
of two trees of real filters and provides six pairs of subbands (for both
the real and imaginary wavelet coefficients) using complex scaling
and wavelet functions. Where the 2D DWT only separates information into
horizontal, vertical and diagonal information, the 2D DTCWT separate the same
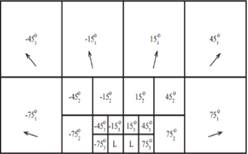
information into six directional subbands, with the angles centered around 15°,
45°, 75°, and their negative equivalents as shown in Figure 1.
functions are
obtained using the product of their associated 1-D scaling and wavelet
functions [12]. The proposed method uses DTCWT which is
an extension of the DWT. The DTCWT, as the name implies, it consists
of two trees of real filters and provides six pairs of subbands (for both
the real and imaginary wavelet coefficients) using complex scaling
and wavelet functions. Where the 2D DWT only separates information into
horizontal, vertical and diagonal information, the 2D DTCWT separate the same
information into six directional subbands, with the angles centered around 15°,
45°, 75°, and their negative equivalents as shown in Figure 1.
|
|
|
|
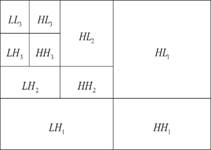
(a) Three levels of 2D DTCWT decomposition. |
(b) Three levels of 2D DWT decomposition |
|
Figure 1.
Multiresolution 2-D wavelet decomposition. |
|
4. The FSPCA-DTCWT Method
As previously mentioned, the focal step in the wavelet-based image
fusion techniques lies in the wavelet coefficients combination, where the main
objective is to reconstruct an image with all useful information contained in
the wavelet coefficients of the decomposed input images. In the present work,
we have processed the approximation and detail wavelet coefficients separately
using different fusion rules; this is due primarily to the different
characteristics of the
wavelet coefficients. The approximation coefficients (low-frequency
subbands) are selected by Max-PCA fusion rule, while the detail coefficients
(which correspond to the high-frequency subbands) are fused using different
selection criteria to integrate the image blocks that have more information
than the image blocks of the second input. The overall schematic diagram
illustrating our proposed fusion method is shown in Figure 2.
Fusion
of approximation coefficients
The coefficients from the low-frequency subbands represent the
approximation component, it contains most of the information and energy of
input images and introduces the visible distortions. Hence, we propose a scheme
by using PCA to merge the approximation coefficients.
The primary goal of PCA is data reduction with the minimum loss of
information, where the first component contains the most representative
knowledge of the original data. A new fusion rule (called Max-PCA) finds the
approximation coefficients of the fused image. Therefore, the process of fusing
the approximation coefficients using the Max-PCA fusion rule consists of the
following steps [14]:
The approximation coefficients of the two input images are arranged in
two column vectors.
Computing the
empirical mean along each column vector and then substrate it from the data of
each column. The resulting matrix is of dimension 2 × n, where n is the length
of each column vector.
Find the covariance matrix L of the resulting matrix in the previous
step.
Compute the eigenvectors ![]() and eigenvalues
and eigenvalues
![]() of
of ![]() and sort them
by decreasing eigenvalue. Note that both
and sort them
by decreasing eigenvalue. Note that both ![]() and
and ![]() are of
dimension
are of
dimension ![]()
Consider the first column of ![]() which
corresponds to larger eigenvalue to compute
which
corresponds to larger eigenvalue to compute ![]() and
and ![]() , where:
, where: ![]() and
and ![]() .
.
Finally, Max-PCA fusion rule is performed to combine approximation
coefficients as follows:
|
|
(2) |
Where ![]() and
and ![]() denote the
coefficients in the approximate subband of the decomposed input images and
denote the
coefficients in the approximate subband of the decomposed input images and![]() indicates the fused coefficient of the approximate
subband.
indicates the fused coefficient of the approximate
subband.
Fusion of detail coefficients
The fusion image process should not remove any
valuable information present in the source images and should preserve the
detailed structures such as edges, strong texture and boundaries of the image.
These details of the image are
Contained in the high-frequency subbands, which are
the subbands containing detail coefficients. Hence, it is imperative to find
the appropriate fusion rule to select the desirable detailed components of the
source images. Conventional methods do not contemplate the neighbouring
coefficients, while a significant correlation exists
between the local neighbouring coefficients of the two source images. We have
proposed a region-based method to merge the detail coefficients in the
decomposition levels. This technique involves the computation of statistical
features such as the standard deviation, spatial frequency and entropy of the
detailed coefficients within a local neighbourhood for the decomposed source
images A and B. This is mainly used to weight the contribution of the pixel
centered in that region.
1. Standard deviation [8]
Standard Deviation (STD) of pixels in a neighbourhood can indicate the
degree of variability of pixel values in that region. The fused coefficients of
the detail subbands have a direct effect on clarity and distortion of the fused
image. Standard deviation of an![]() image is given
by:
image is given
by:
|
|
(3) |
Where ![]() the pixel is value and
the pixel is value and ![]() is the mean value
of the image. Higher value of standard deviation indicates high quality fused
image.
is the mean value
of the image. Higher value of standard deviation indicates high quality fused
image.
2. Spatial frequency [5]
The spatial frequency (SF) of a pixel’s neighbour calculate the
frequency changes along rows and columns of the decomposed source images, it
reflects their activity level and clarity. Spatial Frequency (SF) of an ![]() image is given
by:
image is given
by:
|
|
|
|
|
|
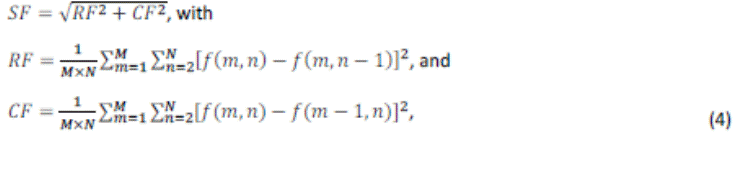
Where![]() and
and ![]() are the row and
column frequencies, respectively. Higher value of SF indicates large
information level in the image.
are the row and
column frequencies, respectively. Higher value of SF indicates large
information level in the image.
3. Entropy [15]
Entropy (EN) used to characterize the texture and to measure the
information quantity contained in an image
|
|
(5) |
where L
represents the number of grey levels and Pl is the ratio of the
number of the pixels with grey value is equal to l over the total number of the
image pixels. Higher entropy value images provide more information than lower
entropy value images [15].
The fused
coefficients of the detail subbands are selected according to the feature
values of SF, STD, and EN. Given two blocks from the first and second input
images (detail subband) if the first block contains better values of SF and STD
than the second block, then the first block will be selected and inserted in
the fused coefficients of the detail subband.
Once the
fused details and approximation coefficients have been calculated, the inverse
DTCWT is applied to provide the final fused image. We can summarize the
FSPCA-DTCWT fusion process as follows:
Step 1.
Apply DTCWT to the input images.
Step 2. For
detail subbands, we divide the detail subband of the input images into several
blocks with a specified size, and then we apply the feature selection rule
using SF, STD, and EN to obtain the fused coefficients of the detail subbands.
Step 3. For
approximation subbands, we apply the proposed Max-PCA fusion rule to obtain the
estimated 2D-DTCWT coefficients of the fused image.
Step 4.
Apply the inverse DTCWT to get the fused image.
Figure 2 shows the main steps of FSPCA-DTCWT algorithm.
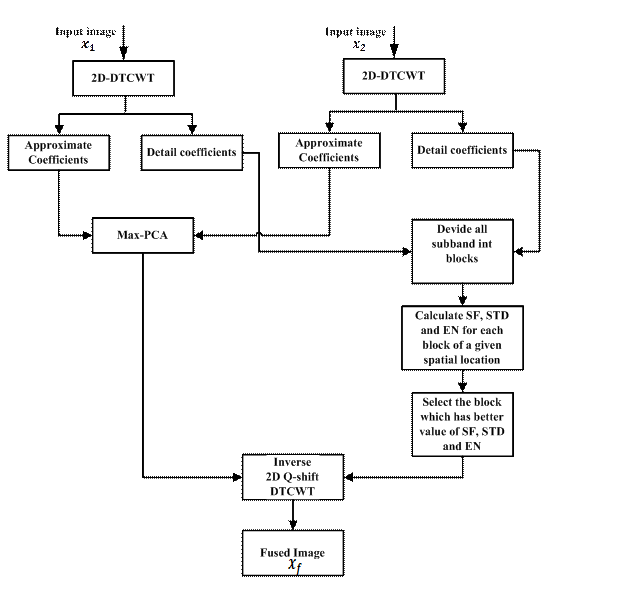
Figure 2.
Schematic diagram of FSPCA-DTCWT fusion algorithm.
5. Experimental Results
This section analyses the performance of the
FSPCA-DTCWT method. FSPCA-DTCWT has been applied to three different medical
image data sets of two modalities, namely: MRI and CT images. Contrary to CT
images, that provide excellent hard tissue imaging such as bones, clear and
detailed images of soft tissue can be obtained from MR images. Fusion of MR and
CT images integrate all possible relevant and complementary information from
both MR/CT into one single image, which will be more useful for a better
medical diagnosis.
The results of FSPCA-DTCWT are compared to different
fusion methods in both Spatial and multiscale transform domains. This study
considered the following multiscale transform methods: Morphological Pyramid
(MP) [16], Discrete Wavelet Transform (DWT) [17], Discrete Cosine Harmonic
Wavelet (DCHWT) [18], Spinning Sharp Frequency Localized Contourlet
Transform(SFLCT_SML)
[19], and Multi-Scale Weighted Gradient-Based Fusion
(MWGF) [20]. Spatial domain methods include Principal Component Analysis (PCA)
[21], Cross Bilateral Filter (CBF) [22] and Bilateral Gradient-Based Sharpness
Criterion (Sharp) [23].
Experiments have been conducted using Matlab 2009b
with three levels of decomposition for all multiscale transform methods. Figure
3 shows the results for the first group of medical images, the latter consists
of two modalities: CT image in Figure 3(a) and MR image in Figure 3(b). The
desired fused image should contain both hard and soft tissue to help the
medical diagnosis of pathologies.
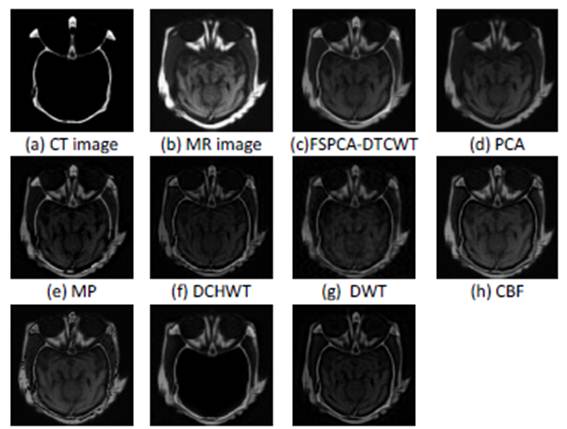
Figure 3. Image fusion
results for the first set of medical images
By observing Fig.3, one can easily conclude that the
fused image obtained by the proposed method Fig 3(c) provides details of bone
structures as well as information about soft tissues. Nevertheless, the results
of the PCA- and the MWGF-based fusion methods (Fig 3(d) and 3(j)) do not
include important information contained in the first source image (Figure 3.a),
while the fused images of MP-, DWT- and Sharp-based fusion methods suffer from
side effects (artefacts and some deformations in different regions).
The results of the second group of images appear in
Figure 4. The input images consist of T1-MR (Fig 1(a)) image that exhibits good
spatial resolution and shows more evident soft tissue details and Magnetic
Resonance Angiogram (MRA) (Fig 4(b)) image showing some abnormality as a
calcified white structure in the image. From Figure 4, it is clear that in this
case the fused image obtained by the FSPCA-DTCWT procedure keeps the highest
contrast and is more informative than the fused images obtained by the other
fusion methods (the PCA-, Sharp-, DWT-, CBF-, MWGF- based fusion methods).
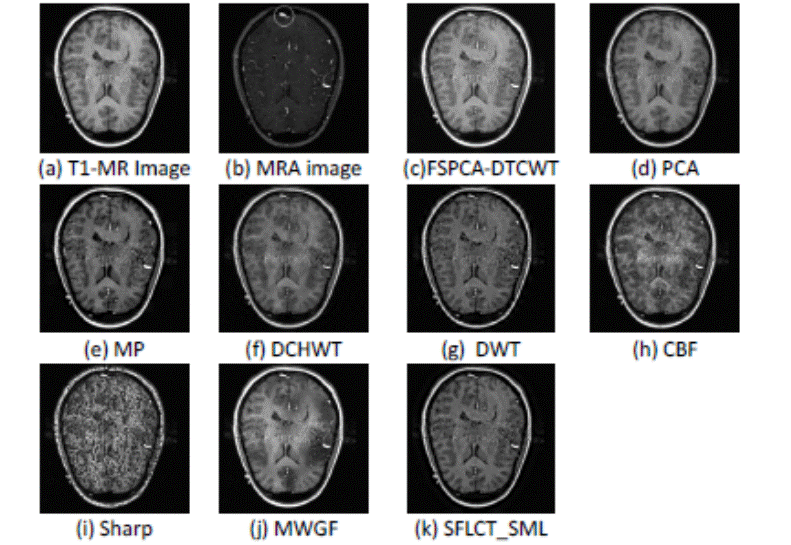
Figure
4. Image fusion results for the second set of medical images
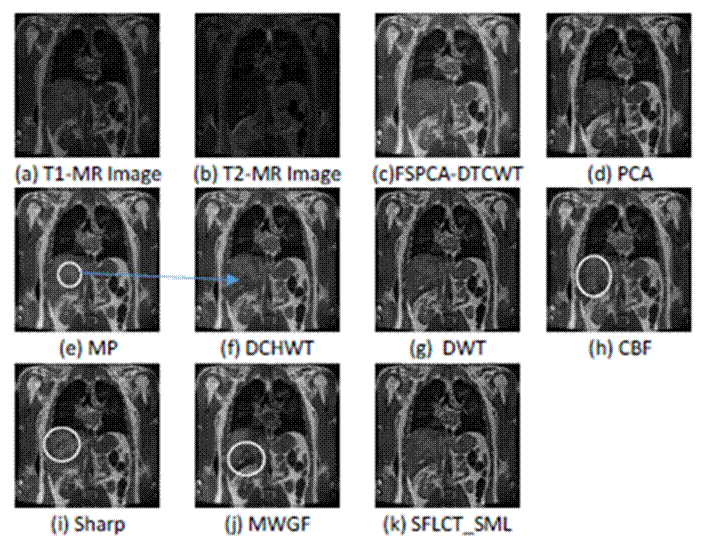
Figure
5. Image fusion results for the third set of medical images
In the third group of medical images, images a and b (Fig. 4(a)) and
4(b)) are MR-T1 and MR-T2 image, respectively. We can see that the fusion
result in Fig. 4(e) obtained with MP method loses some of the information in
image b. It is also clear that the fuse d images of CBF, Sharp and MWGF fusion
methods suffer from deformations of tissue (area marked by the ellipse in Fig.
5(h-j))). The fused images obtained by SFLC T_SML- and DCHWT-based fusion
methods have good visual
quality as the proposed method. However, the visual comparison is not
sufficient to evaluate the fusion methods as in this case. Therefore, a
quantitative analysis using five recent and widely used fusion performance
metrics were used, namely: Standard Deviation (STD) [8], Entropy (EN)[15],
Fusion Factor (FF)[8], Correlation Coefficient (CC)[24] and Visual Information
Fidelity(VIF)[25].
VIF is a full reference image quality assessment metric. It is based on
natural scene statistics and the notion of image information extracted by the
human visual system (HVS). The quantity of visual information is considered as
the amount of information extracted by the HVS from the reference image after
it has passed through the distortion channel. The visual quality of the
distorted image should relate to the amount of information that can be
extracted by the HVS from the test image relative to the reference image
information. If the amount of information that is extracted is very close to
the reference image information, then the visual quality of the distorted image
is very high since no loss of information occurs in the distortion channel.
More details about the mathematic development of VIF can be found in [25] and
[26].
FF [8] stand for the total amount of similarity between the fused image
F and the source images A and B, FF is given by:
![]()
Where MI is the mutual information between source
images and the fused image. Therefore, a higher value of FF shows that a larger
amount of information was preserved in the fused image which indicates better
fusion results. If the two images, A and F, are independent, then the mutual
information similarity is zero. If the two images, A and F, are identical, all
the information of A is shared with F. This performance metric can be used to
help observers make quicker and more accurate decisions.
The values of the quantitative assessments for the two
groups of input images (Figs. 3, 4 and Fig. 5) appear in Tables 1, 2 and 3
respectively. From table1and 2 (Each column’s best result is shown in boldface).
We can conclude that FSPCA-DTCWT algorithm outperforms the other one in terms
and has better values of fusion metrics (in most of the cases). For example,
the PCA- and Sharp-based fusion methods have the best values of FF (Table 1),
but the visual quality of these result show a poor quality and one can observe
that the corresponding fused images suffer from loss information and presence
of new patterns that do not exist in any of the sources images. Similarly, the
DCHWT-and Sharp-based fusion methods have the highest values of EN and FF
(Table 2). However, the visual results in (Fig.4 i and f) indicate that the
fused image obtained by the DCHWT-based fusion method has poor contrast as
compared with that yielded with the FSPCA-DTCWT algorithm, while the fused
image obtained by Sharp-based fusion method failed in preserving all relevant
structures and loss of important visual information.
|
Table 1. Performance comparison for the first group of medical images. |
|||||
|
Methods |
STD |
EN |
FF |
VIF |
CC |
|
FSPCA-DTCWT |
34.5447 |
6.1646 |
2.8968 |
0.6229 |
0.7081 |
|
PCA |
28.3806 |
5.6220 |
5.2781 |
0.2843 |
0.50508 |
|
MP |
29.2381 |
5.5794 |
1.9303 |
0.4380 |
0.6558 |
|
DWT |
22.0508 |
5.4541 |
2.1945 |
0.3313 |
0.6953 |
|
DCHWT |
23.3187 |
5.7434 |
1.7824 |
0.3558 |
0.6761 |
|
CBF |
30.6469 |
5.9157 |
2.8944 |
0.4438 |
0.6329 |
|
Sharp |
30.9918 |
5.8097 |
5.5296 |
0.3501 |
0.5817 |
|
MWGF |
33.2277 |
5.0722 |
2.1105 |
0.4569 |
0.6737 |
|
SFLCT_SML |
22.5327 |
5.4948 |
1.9197 |
0.3539 |
0.6912 |
|
Table 2. Performance comparison for the second group
of medical images. |
|||||
|
Methods |
STD |
EN |
FF |
VIF |
CC |
|
FSPCA-TCWT |
67.2241 |
6.0301 |
4.2017 |
0.8684 |
0.9127 |
|
PCA |
56.5746 |
5.7044 |
5.2143 |
0.7448 |
0.9016 |
|
MP |
54.5920 |
5.8559 |
3.9943 |
0.7721 |
0.8781 |
|
DWT |
49.0719 |
5.8477 |
3.5730 |
0.5953 |
0.9027 |
|
DCHWT |
50.4815 |
6.2555 |
3.5623 |
0.6693 |
0.9108 |
|
CBF |
55.5992 |
5.8597 |
3.9321 |
0.7176 |
0.8836 |
|
Sharp |
58.9186 |
5.8815 |
6.4834 |
0.4754 |
0.7757 |
|
MWGF |
61.4758 |
5.8911 |
4.4029 |
0.8192 |
0.8860 |
|
SFLCT_SML |
50.4341 |
5.7974 |
3.5792 |
0.6818 |
0.8962 |
|
Table 3. Performance comparison for the third
group of medical images. |
|||||
|
Methods |
STD |
EN |
FF |
VIF |
CC |
|
FSPCA-DICWT |
28.7078 |
6.6174 |
4.06653 |
0.9199 |
0.9264 |
|
PCA |
23.6914 |
6.3015 |
4.7015 |
0.6890 |
0.9216 |
|
MP |
28.6009 |
6.4188 |
3.5305 |
0.9439 |
0.9108 |
|
DWT |
24.0218 |
6.2701 |
3.3806 |
0.6827 |
0.9187 |
|
DCHWT |
23.6866 |
6.2919 |
3.1834 |
0.6664 |
0.9147 |
|
CBF |
23.4422 |
6.2059 |
4.0970 |
0.6845 |
0.9269 |
|
Sharp |
25.8353 |
6.4203 |
3.9854 |
0.7660 |
0.9097 |
|
MWGF |
28.7378 |
6.4916 |
5.7157 |
0.8795 |
0.8950 |
|
SEFLCT-SML |
28.2195 |
6.5226 |
6.7962 |
0.7629 |
0.8592 |
Similarly, the results in Table 5 give the advantage to FSPCA-DTCWT
algorithm with respect to the different fusion methods belonging to the spatial
domain and the transformation domain. SFLCT_SML- and CBF- based fusion method
have
the best value of FF and CC, respectively. However, the individual
comparisons of the proposed method with SFLCT_SML and CBF have proved the
superiority of the proposed method in the most cases of the evaluation criteria
used in this paper. Moreover, comparison should be made on the basis of both,
visually and quantitatively. For example, MP method has higher VIF value but
has a poor visual quality than the proposed method and failed to capture all
relevant information contained in the source images (it can be easily observed
from Fig.5)
From the above discussion, one can conclude that the quantitative results of
the proposed method are consistent with the visual analysis results.
Through the obtained results of the qualitative evaluation and
quantitative indicators, we can see that FSPCA-DTCWT algorithm is found to be
better than other transform domain methods and spatial domain methods. Also,
FSPCA-DTCWT algorithm is able to preserve detail information such as edges and
boundaries.
6. Conclusion
In this paper, we have proposed a new fusion method using DTCWT which is
approximately shift invariant and has the high directionality properties that improve
the quality of fusion results. The major contributions of this paper are
twofold. First, we used a Maximum-PCA fusion rule to merge the approximation
coefficients. Second, a feature selection process is proposed to select the
blocks containing the most essential information from the sources images.
The experimental results show that the proposed method has better
performance than both multiscale transform domain methods and spatial domain
methods in the visual effects and quantitative fusion evaluation measures.
7. Declaration of conflicts
This paper
is a revised and expanded version of a paper entitled ‘An Efficient Algorithm
for Multimodal Medical Image Fusion based On Feature Selection and PCA Using
DTCWT.’ presented at the International Workshop on Medical Technologies 2017
co-located with ICHSMT2017, Tlemcen, Algeria, 10– 12October 2017 [1].
8. Authors’ biography
Abdallah Bengueddoudj was born in Bordj Bou Arreridj (Algeria),
on August 1988, he received the B.S. degree in electronic in 2009 and the
Master degree in electrical engineering in 2011. He is currently a candidate
for the Ph.D. degree in electrical engineering and industrial informatics. His
research interests include biometric systems, multiresolution and wavelet
analysis, pattern recognition and image processing.
Zoubeida Messali was born in Constantine (Algeria), on
November 1972, she received the B.S. degree in electronic engineering in 1995,
the Master degree in signal and image processing in 2000 and Ph.D. degree in
2007 from Constantine University, Algeria. Since 2002, she has been working as
a Teaching Assistant in the Department of Electronics at Msila University, and
university of Bordj Bou Arreridj, Algeria. Her research interests include
distributed detection networks, multiresolution and wavelet analysis,
estimation theory, and medical image processing.
9. REFERENCES
[1]A. Bengueddoudj and Z. Messali, “An Efficient Al
gorithm for Multimodal Medical Image Fusion based On Feature Selection and PCA
Using DTCWT.”, Med ical Technologies Journal, vol. 1, no. 3, pp. 60-61, Sep.
2017.https://doi.org/10.26415/2572-004X-vol1iss3p60-61
[2]A. P. James and B. V. Dasarathy, "Medical
image fusion: A survey of the state of the art," Inf. Fusion, vol. 19, pp.
4–19, 2014. https://doi.org/10 .1016/j.inffus.2013.12.002
[3]D. Delbeke, R. E. Coleman, M. J. Guiberteau, M. L.
Brown, H. D. Royal, B. a Siegel, D. W. Townsend, L. L. Berland, J. A. Parker,
G. Zubal, and V. Cronin, "Procedure Guideline for SPECT/CT Imaging
1.0.," J. Nucl. Med., vol. 47, no. 7, pp. 1227–34, Jul. 2006.
PMid:16818960
[4]Q. Wang, S. Li, H. Qin, and A. Hao, "Robust
multi-modal medical image fusion via anisotropic heat diffusion guided low-rank
structural analysis," Inf. Fusion, vol. 26, pp. 103–121, 2015.
https://doi.org/10.1016/j.inffus.2015.01.001
[5]P. Ganasala and V. Kumar, "CT and MR Image
Fusion Scheme in Nonsubsampled Contourlet Transform Domain," J. Digit.
Imaging, vol. 27, no. 3, pp. 407–418, Jun. 2014. https://doi.org/10.1007/s10278-013-9664-xPMid:24474580
PMCid:PMC4026459
[6]A. Saleem, A. Beghdadi, and B. Boashash, “Image fu
sion-based contrast enhancement,” EURASIP J. Image Video Process., vol. 2012,
no. 1, p. 10, 2012. https://doi.org/10.1186/1687-5281-2012-10
[7]S. Daneshvar and H. Ghassemian, "MRI and PET
image fusion by combining IHS and retina-
inspired models," Inf. Fusion, vol. 11, no. 2,
pp. 114–123, Apr. 2010. https://doi.org/10.1016/j.inffus.2009.05.003
[8]R. Singh and A. Khare, "Fusion of multimodal
medical images using Daubechies complex wavelet transform – A multiresolution
approach," Inf. Fusio n, vol. 19, pp. 49–60, Sep. 2014.
https://doi.org/10.1016/j.inffus.2012.09.005
[9]K. Amolins, Y. Zhang, and P. Dare, "Wavelet
based image fusion techniques — An introduction, review and comparison,"
ISPRS J. Photogramm. Remote Sens., vol. 62, no. 4, pp. 249–263, Sep. 2007.
https://doi.org/10.1016/j.isprsjprs.2007.05.009
[10]Li, Hui, B. S. Manjunath, and Sanjit K. Mitra,
"Multisensor image fusion using the wavelet transform," Graphical
models and image processing., vol. 57, no. 3, pp. 235–245, 1995.
https://doi.org/10.1016/j.isprsjprs.2007.05.009
[11]I. W. Selesnick, R. G. Baraniuk, and N. G.
Kingsbury, "The dual-tree complex wavelet transform," IEEE Signal Process. Mag., vol. 22, no. 6, pp. 123–
151, 2005. https://doi.org/10.1109/MSP.2005.1550194
[12] G.
Chen and Y. Gao, "Multisource image fusion based on double density
Dual-tree Complex Wavelet transform," 2012 9th Int. Conf. Fuzzy Syst.
Knowl. Discov., vol. 1, no. Fskd, pp. 1864–1868, May 2012. https://doi.org/10.1109/FSKD.2012.6233906
[13]P. Ramírez-Cobo, K. S. Lee, A. Molini, A.
Porporato, G. Katul, and B. Vidakovic, "A wavelet-based spectral method
for extracting self-similarity measures in time-varying two-dimensional
rainfall maps," J. Time Ser. Anal., vol. 32, no. 4, pp. 351– 363, Jul.
2011. https://doi.org/10.1111/j.1467-9892.2011.00731.x
[14]A. Bengueddoudj, Z. Messali, and V. Mosorov,
"A Novel Image Fusion Algorithm Based on 2D Scale-Mixing Complex Wavelet
Transform and Bayesian MAP Estimation for Multimodal Medical Images," J.
Innov. Opt. Health Sci., vol. 10, no. 6, p. 1750001, Nov. 2016.
[15]H. Jiang and Y. Tian, "Fuzzy image fusion
based on modified Self-Generating Neural Network," Expert Syst. Appl.,
vol. 38, no. 7, pp. 8515–8523, 2011. https://doi.org/10.1016/j.eswa.2011.01.052
[16]N. Uniyal, "Image Fusion using Morphological
Pyramid Consistency Method," vol. 95, no. 25, pp. 34–38, 2014.
PMCid:PMC4271098
[17]L. Chiorean and M.-F. Vaida, "Medical image
fusion based on discrete wavelet transform using Java technology," in
Proceedings of the ITI 2009 31st International Conference on Information
Technology Interfaces, 2009, pp. 55–60. https://doi
.org/10.1109/ITI.2009.5196054
[18]B. K. Shreyamsha Kumar, "Multifocus and
multispectral image fusion based on pixel significance using discrete cosine
harmonic wavelet transform," Signal, Image Video Process., vol. 7, no. 6,
pp. 1125–1143, Nov. 2013. https://doi.org/10.1007/s1176 0-012-0361-x
[19]Q. U. X. Y. A. N. Jing-wen and Y. Gui-de,
"Sum-modified-Laplacian-based Multifocus Image Fusion Method in Cycle
Spinning Sharp Frequency Localized Contourlet Transform Domain," no.
60472081.
[20]Z. Zhou, S. Li, and B. Wang, "Multi-scale
weighted gradient-based fusion for multi-focus images," Inf. Fusion, vol.
20, no. 1, pp. 60–72, 2014. https ://doi.org/10.1016/j.inffus.2013.11.005
[21]V.P.S. Naidu and J.R. Raol, "Pixel-level
Image Fusion using Wavelets and Principal Component Analysis," Def. Sci.
J., vol. 58, no. 3, pp. 338–35 2, 2008. https://doi.org/10.14429/dsj.58.1653
[22]B. K. Shreyamsha Kumar, "Image fusion based
on pixel significance using cross bilateral filter," Signal, Image Video
Process., vol. 9, no. 5, pp. 1193–1204, Jul. 2015. https://doi.org/10.1007/s11760-013-0556-9
[23]Tian, J., Chen, L., Ma, L., and Yu, W,
"Multi-focus image fusion using a bilateral gradient-based sharpness
criterion," vol. 284, no. 1, pp. 80–87, 2 011.
https://doi.org/10.1016/j.optcom.2010.08.085.
[24]J. L. Crowley and J. Martin, "Experimental
comparison of correlation techniques," in IAS-4, International Conference
on Intelligent Autonomous Systems, Karlsruhe, 1995.
[25]H. R. Sheikh and A. C. Bovik, "Image
information and visual quality," IEEE Trans. Image Process., vol. 15, no.
2, pp. 430–444, 2006. https://doi.org/ 10.1109/TIP.2005.859378 PMid:16479813
[26]Han Y, Cai Y, Cao Y, Xu X. "A new image
fusion performance metric based on visual information fidelity, " Inf
Fusion., vol. 14, no. 2, pp. 127–135, 2013. https://doi.o rg/10.1016/j.inffus.2011.08.002.
PMid:16479813