A COMPACT SIFT-BASED STRATEGY FOR VISUAL INFORMATION RETRIEVAL IN LARGE
IMAGE DATABASES
Type of article: Original
Bernardo F. Cruz1 , Joaquim T. de Assis1,
Vania V. Estrela2, Abdeldjalil Khelassi3
1Universidade do Estado do
Rio de Janeiro, Instituto Politécnico, 28630-050 – Nova Friburgo, RJ, Brazil
2Telecommunications
Department, Federal Fluminense University (UFF), RJ, Brazil
3Abou Beker Belkaid
University of Tlemcen, Algeria
Abstract:
This paper applies the Standard Scale Invariant Feature Transform (S-SIFT)
algorithm to accomplish the image descriptors of an eye region for a set of
human eyes images from the UBIRIS database despite photometric transformations.
The core assumption is that textured regions are locally planar and stationary.
A descriptor with this type of invariance is sufficient to discern and describe
a textured area regardless of the viewpoint and lighting in a perspective image,
and it permits the identification of similar types of texture in a figure, such
as an iris texture on an eye. It also enables to establish the correspondence
between texture regions from distinct images acquired from different viewpoints
(as, for example, two views of the front of a house), scales and/or subjected
to linear transformations such as translation. Experiments have confirmed that
the S-SIFT algorithm is a potent tool for a variety of problems in image
identification.
Keywords: Scale Invariant Feature
Transform, texture description, computer vision, image databases, iridology, content-based
image retrieval, CBIR.
Corresponding author: Bernardo F. Cruz, Ould Amer Nassima, Universidade
do Estado do Rio de Janeiro, Instituto Politécnico, 28630-050 – Nova Friburgo,
RJ, Brazil. bernardofcruz3@gmail.com
Received: 22 June, 2019, Accepted: 11 July, 2019, English editing: 12
July, 2019, Published: 13 July, 2019.
Screened by iThenticate..©2017-2019 KNOWLEDGE
KINGDOM PUBLISHING.
1. INTRODUCTION
The immense growth of digital images in today’s
society requires efficient Big Data (BD)-oriented management, storage, retrieval
and handling of visual information. A Content-Based
Image Retrieval (CBIR) System (CBIRS) seeks to match a query image to one or
more similar imageries from an extensive database for additional analysis and
retrieval. CBIR involves images searches
relying on some similarity measure (comparison criteria or metrics) for the
visual content appraisal of the query imagery and choose the best matches. This manuscript focuses on the iris image
analysis, which has applications in biometrics and clinical exams.
The
iris is a prevalent biometric trait owing to the trustworthiness and high
accuracy of the majority of the deployed iris recognition schemes, which
resemble the Daugman’s ground-breaking method [22]. Nevertheless,
the application scenarios for these systems are restricted primarily because of
the indispensable near infrared (NIR) illumination. NIR illumination presents a
distance related constraint since, for suitable eye images, the individual has
to stand very close to the camera. Thus, a looked-for feature of an iris
identification framework is to perform competently with color iris imageries.
This characteristic is obligatory for less controlled iris recognition as it
will automatically tolerate the user recognition at a more considerable
distance compared to the circumstance using NIR illumination.
Complete
eye exams are important for several motives since eyesight may transform very progressively
over time, and one may not even acknowledge the necessity a stronger treatment.
An ophthalmologist also performs several
tests, which will rule out eye maladies, e.g., cataracts, glaucoma, or retinal
problems.
Together
with eye-related worries, physicians can spot other health concerns throughout
a complete eye examination. Some health problems that may be diagnosed via an
eye exam are listed below [21, 35, 36].
a) Diabetes affects the small retina capillaries so that these small blood
vessels discharge blood or a yellowish fluid and thus characterize a condition named
diabetic retinopathy.
b) Hypertension may cause the eye blood vessels to show bends, tears or kinks due
to high blood pressure.
c) Autoimmune
disorders
like Lupus can provoke eye inflammation.
d) High
cholesterol may
leave the cornea yellowish or with a yellow ring around it and with plaques in
the retina blood vessels.
e) Thyroid disease (Graves Disease) can cause bulging eyes
or swollen eyeballs.
f) Cancer: Ocular melanoma can develop in the eye pigmentation cells.
A comprehensive eye test can also aid detect skin cancer because the eyelid can
have basal cell carcinomas that can even affect the brain.
g) Neck tumors and
aneurism can
be detected when there is a droopy eyelid or unevenly shaped pupils.
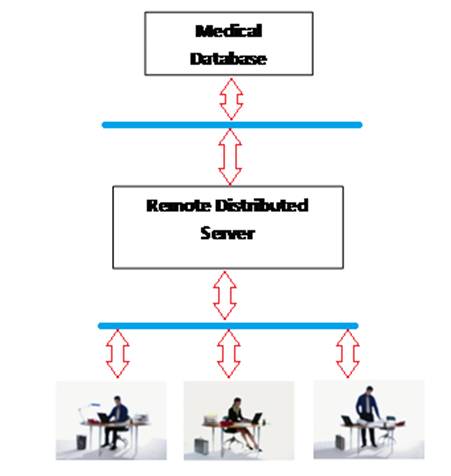
Figure 1 – CBIRS Architecture.
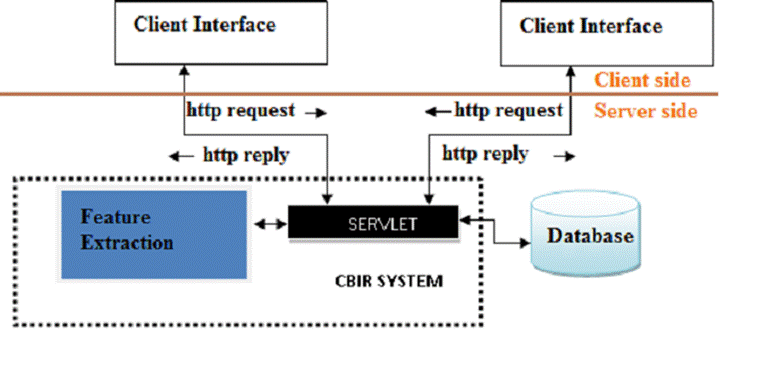
Figure 2 – CBIRS from the Internet point of view.
The increasing size and
complexity of image databases entail descriptors for textured areas, which do
not show a discrepancy after affine and photometric transformations in addition
to being robust to segmentation [19, 21]. In general, they deliberate that the
textured regions are planar and stationary (the statistical distribution is
spatially homogeneous) inside a neighborhood. This degree of invariance is
enough to depict textured regions regardless of their viewpoint and lighting
[5, 16, 19]. Such a descriptor simplifies the identification of similar types
of texture patches in an image, such as an iris area from a given eye, and thus
it allows matching images acquired from different standpoints, such as two
pictures of the front of a house. Intra-image (local) matching happens inside a
frame, and it identifies a known textured area on different surface patches. On
the other hand, inter-image (global) matching seeks the analogous texture areas
in different frames that correspond to the same surface patch. This research
effort aims at discovering a suitable texture descriptor to target both
situations automatically, regardless of viewpoints
Local traits
can be efficaciously used for object categorization and classification. Unique
local descriptors that are invariant to image transformations, robust to
occlusion, and do not call for segmentation are adequate to baseline matching,
target discovery, texture recognition, Image Retrieval (IR), robot recognition,
video information mining, creation of panoramas, and identification of object
classes to name a few applications. Given invariant region descriptors, it is
necessary to verify if they expediently characterize regions as well as if the
detection framework is viable. Detectors can have a large number of potential
descriptors, and they can use different distance measures to emphasize various
imagery properties, e.g., pixel intensities, color, texture, edges, etc. This
work is centered on descriptors computed from gray-level images.
This paper presents a simple method to lessen the size, complexity and
matching time of feature sets obtained with the Standard SIFT (S-SIFT)
algorithm [3, 4, 5] in biometry and image retrieval. This simple scheme takes
advantage of the use of a patch of the Iris to come up with a necessary and
sufficient number of SIFT features to describe an individual’s iris to index a
database and recognize individuals. Experimental results using digital images
from eyes without any pre-processing demonstrate that there is a minimal loss
of precision in feature retrieval while accomplishing a noteworthy reduction of
the image descriptor dimension and matching time.
This paper tackles an application of the
S-SIFT technique for CBIR of the irises in healthcare/biometrics, assuming that
access is global and secure since it is more reasonable to think about internet
based systems as seen in Figure 1 and 2.
In this text, Section II situates the importance of CBIRSs in biomedical
settings. Section III explains the basics of the SIFT technique. Experiments
and performance evaluation are discussed in Section IV. Conclusions are
examined in Section V.
2. CONTENT-BASED IMAGE RETRIEVAL (CBIR)
Since an IR system
aims to find query images inputted by users, the first setback is to deal with
how to express clearly the users’ intention. The most primitive way that comes
to mind is to employ a textual (wordily) description of the scenario sought
(query image). Nevertheless, when it comes to biomedical records, this
methodology can lead to misjudgement and lots of useless data [29, 30].
As Internet technologies
and the ability to handle vast data volumes augmented, other research kinds became
feasible, such as Query by Example (QBE), where a sample image is used as to
identify or illustrate a given pathology. A more strict
CBIR definition as a QBE is found in [26-27]:
For an
extensive image database U, a picture
representation p relying on image primitives
(for example, pixel intensities) and a dissimilarity measure D(p,q) defined in the image domain, find (using a specific
index) the M images p∈U with the lowest
dissimilarity to the query image q, the consequential
M images are ranked in ascending
dissimilarity.
A convenient biomedical
architecture dedicated to CBIR would be an Internet-based
framework (refer to Figures 1 and 2). Within the milieu of CBIR, the client’s
information query should be unambiguously performed by the visual content of
the query image. When a user is in quest
of a specific entity or the objects very similar to a specific picture, e.g.,
an infected tissue that looks to a great extent like a sample. In such
circumstances, a photo is better than any phrases to convey without a doubt the
user’s interest. Still, users who are merely concerned with a generic category
of objects, for instance, “tissues”, can never be able to express this
information need by submitting imagery of a specific tissue. They will not get
satisfactory results by doing so. Some researchers address this as the semantic
gap problem. To surpass the semantic void is to put up a structure able of seizing
a semantic notion from a single specific image, which is unattainable because a
high-level concept can only be generalized from a massive amount of features and
spending computational intelligence techniques.
The advancement of CBIR ontologies [14, 22] still
attracts increasing interest. Using both a textual description (e.g., metadata)
and visual features for knowledge retrieval signs towards multi-disciplinary
techniques [7, 21, 22]. Basic questions endure in areas such as classification
and indexing, vocabulary handling, the user’s needs understanding, relevance
analysis, similarity measures, index granularity, scaling and presentation of the
retrieval outcomes. There is a strong clue that employing textual and visual
data may improve VIR system effectiveness. To close, when relating text
retrieval systems to IR frameworks, [9] it is evident that IR systems lack
effectiveness. IR effectiveness studies require extensive collections of
images, novel representation/indexing methodologies, benchmark queries and the
embracing of a set of assessment metrics. There are several distresses when it
comes to designing CBIRSs for biomedical applications:
a)
discovery of prospective users;
b)
revision of the current
techniques for CBIR;
c)
preservation of an extensive
record of real medical cases and images;
d)
choosing upon image features
to be removed and which similarity metrics are needed;
e)
build a web-deployable the
system;
f)
certified access to the CBIR structure;
and
g)
web-based robust GUI.
CBIR is
reliant on primitive features automatically mined from the images themselves
[8, 11, 13, 24, 25] and it entails proper tools for image indexing in addition
to retrieval. Queries to CBIRSs are largely expressed as picture instances of
the kind of image or visual attribute sought. An overview of some tactics for
image similarity matching in biomedical database retrieval is given in [7, 29,
30] where the difficulty to express high-level image prerequisites as low-level
image clues, such as feature extraction and feature matching is also discussed.
S-SIFT features are distinctive, invariant to image
transformations, and robustly describe, and help to match visual content related
to altered views of a scene, but they are typically large and slow to figure.
3. SCALE INVARIANT FEATURE TRANSFORM (SIFT)
This manuscript works with a segmented piece of the
iris from the eye image to avoid part of the heavy computational burden of
applying the S-SIFT and, according to [12], comprises four major stages:
(1) Scale-Space Peak Selection
(SSPS) identifies possible interest points via image scanning over the location
and scale with for example a Gaussian pyramid with a subsequent search for
local peaks (designated key points) in a succession of Difference-of-Gaussian (DoG) images.
(2) Key Point Localization
(KPL) locates candidate key points with sub-pixel accuracy and eliminates
unstable ones.
(3) Orientation Assignment
(OA) detects the dominant alignments for each key point belonging to its local
image patch. The location, orientations, and scale attained for each key point
permit the S-SIFT to create a canonical key point interpretation that does not
vary with similarity transformations.
(4) The Key Point Descriptor
(KPD) constructs for each key point a corresponding local image descriptor with
the image gradients within its local neighborhood.
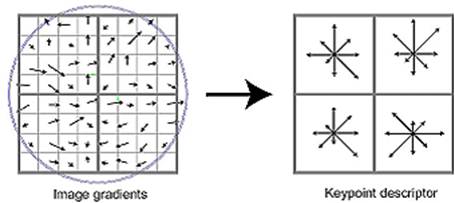
Figure 3 - A key point descriptor
results from the application of the gradient magnitude m(x, y) and orientation Ɵ(x, y) nearby the
key point, and followed by a circular Gaussian window filter (indicated by the
circle above). Each orientation histogram is calculated from a 4×4 pixel support window divided over 8 orientation bins [5].
This paper discusses the KPD
stage of the S-SIFT procedure to typify each image by a collection of
descriptors formed with a patch of pixels instead of the whole iris. Note that
this local neighborhood must be centered
about the key point location beforehand, rotated using its dominant
orientations as a basis with appropriate scaling. The goal is to find a patch
descriptor that is compact, extremely distinctive (i.e., patches around
dissimilar key points map to different representations) and nevertheless robust
to variations in lighting and camera viewpoint (e.g., if the same key point
appears in different images of the same subject, then they spawn similar
representations). Distinct methods (like calculating the normalized correlation
among image patches) do not perform acceptably [12] since they are too
sensitive to registration errors and non-rigid transformations. The emblematic
S-SIFT key point descriptor originates from samples of the magnitudes as well
as orientations of the intensity gradient in the patch surrounding the key
point, and from smoothed orientation histograms that portray the significant
aspects of the patch. A 4×4 array of histograms, each one having 8 orientation
bins, portrays adequately the irregular spatial patch structure. Next, the magnitude
length of this 128-element Feature Vector (FV) is normalized to the unit,
followed by the application of a threshold to exclude small valued elements.
The S-SIFT descriptor representation is noteworthy in several ways:
(1) the representation avoids
problems caused by boundary effects (smooth position, orientation and scale
alterations do not impact the FV radically);
(2) a 128-element FV is a
realistic description for the patch of pixels; and
(3) the depiction is
remarkably resilient to deformations like those caused by perspective effects
albeit not resilient to affine transformations.
These attributes yield an
excellent matching performance [14]. In contrast, the S-SIFT FV construction is
intricate, as well as the choices behind its specific design are unclear
([12]). This initial research goal is to explore more straightforward
possibilities and to assess the tradeoffs
empirically. The proposed alternative use of S-SIFT to a segmented piece of the
iris is less complex, more compact, quicker to respond and as satisfactory as
applying the S-SIFT descriptor to all iris. The S-SIFT source code has been
used [3, 4, 5] and restricts modifications to the KPD stage to warrant accurate
outcomes.
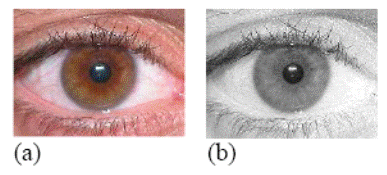
Figure 4 – (a) Eye
image, and (b) Its R component [31].
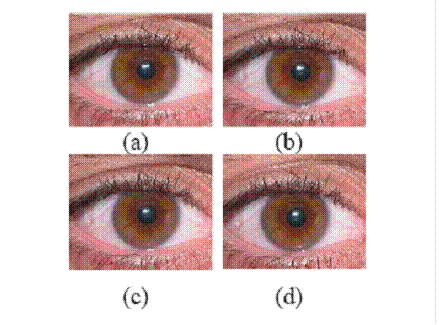
Figure 4 – Four images of the same
individual’s eye [31]: (a) 3.1, (b) 3.2, (c) 3.3and (d) 3.4.
Lowe
[3, 4, 5] proposed the S-SIFT technique to associate a scale-invariant region
detector and a descriptor that rests on the gradient distribution in the
identified regions. A 3D histogram of gradient positions and orientations
accounts for the descriptor (refer to Fig. 1 for an illustration). The gradient
magnitude weights the contribution of the location and orientation bins. The
quantization of gradient locations and orientations robustify
the descriptor concerning small geometric distortions and insignificant errors
in the region detection. The geometric histogram and the shape context
implement an equivalent idea and are very similar to the S-SIFT descriptor.
Both methods build a histogram describing the edge distribution in a region.
These descriptors were efficaciously used, for example, for the recognition of
drawings relying on edges as features.
This
work employs S-SIFT to mine distinctive invariant image features that can help
to perform accurate matching between distinct observations of an object or
scene. It transforms image data into features that do not vary when subjected
to scaling and rotation. These structures provide robust matching across an
ample range of affine distortions, modifications in the 3D viewpoint, presence
of noise, and illumination change. These features are, to a high degree
distinctive, in the sense that a particular feature can be correctly matched to
an extensive visual feature database with high probability. This paper also
refers to tests using these image descriptors for biometric recognition. The
recognition stage matches individual traits to a feature database containing
known objects via a fast nearest-neighbour algorithm, followed by a Hough
transform to discriminate clusters that are part of a single object, and, as a
final point, perform verification via least-squares to discover consistent pose
parameters. This approach identifies robustly objects immersed in clutter and
contingent on occlusion while accomplishing near real-time execution.
4. PERFORMANCE EVALUATION
The
following experiments were conducted using the human eye database UBIRIS, from
the University of Beira Interior. It has 1877 JPEG images from 241 people in
diverse situations [6, W]. Since these images are RGB, we decided to test the
best option in order to simplify the input images and opted for the use of the
R component in the experiments shown below.
The first phase discerns
feature points in each image. The S-SIFT key point detector [5] was preferred
for its invariance to image transformations. Typically, an image has several
thousand S-SIFT key points. Other feature detectors from [16, 19] could also be
utilized. Besides the key point locations themselves, S-SIFT makes available a
local descriptor per key point.
The descriptors have been
applied to real eye images subject to different photometric and geometric
transformations for different scene types.



Figure 5 –
Comparisons between images of the same individual.
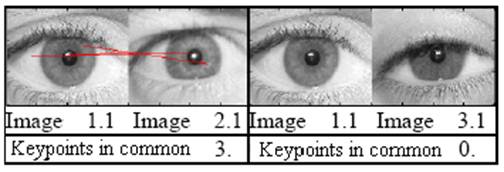
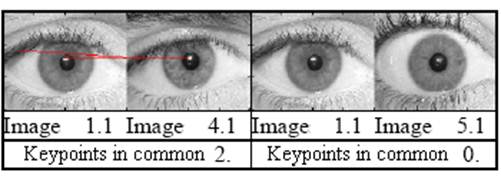
Figure 6 –
Some results of comparisons between the individual from Fig.3 and 4 different
people.